The Art of Hybrid Architectures

In my previous article, I discussed how morphological feature extractors mimic the way biological experts visually assess images. This time, I want to go a step further and explore a new question:Can different architectures complement each other to build an AI that “sees” like an expert? Introduction: Rethinking Model Architecture Design While building a high […]
AI Agents from Zero to Hero — Part 3
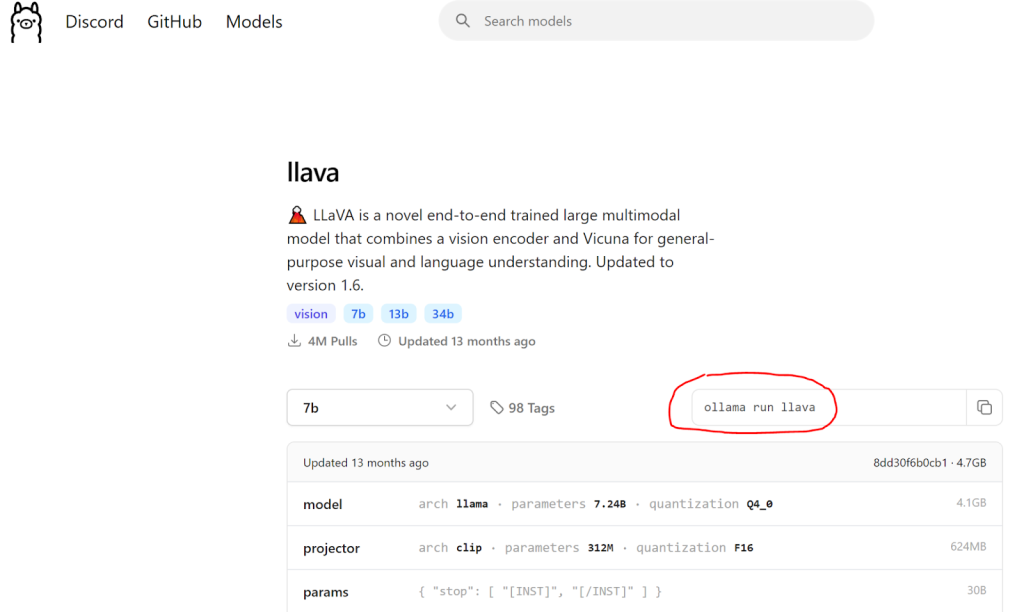
Intro In Part 1 of this tutorial series, we introduced AI Agents, autonomous programs that perform tasks, make decisions, and communicate with others. In Part 2 of this tutorial series, we understood how to make the Agent try and retry until the task is completed through Iterations and Chains. A single Agent can usually operate […]
Detecting Text Ghostwritten by Large Language Models – The Berkeley Artificial Intelligence Research Blog
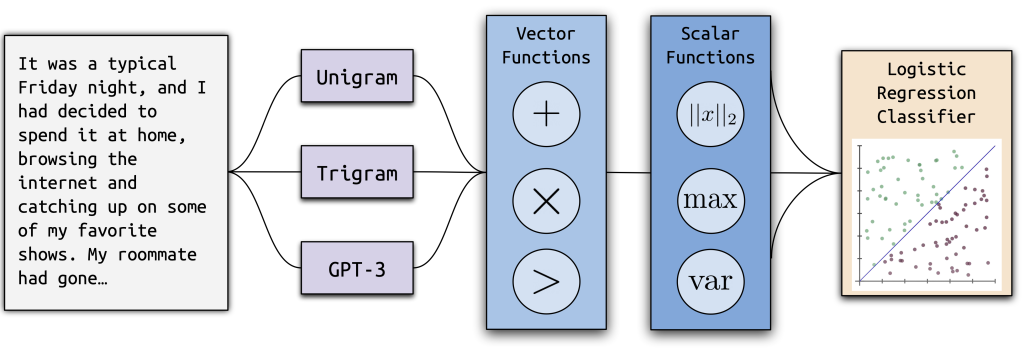
The structure of Ghostbuster, our new state-of-the-art method for detecting AI-generated text. Large language models like ChatGPT write impressively well—so well, in fact, that they’ve become a problem. Students have begun using these models to ghostwrite assignments, leading some schools to ban ChatGPT. In addition, these models are also prone to producing text with factual […]
Data Science: From School to Work, Part III

Introduction Writing code is about solving problems, but not every problem is predictable. In the real world, your software will encounter unexpected situations: missing files, invalid user inputs, network timeouts, or even hardware failures. This is why handling errors isn’t just a nice-to-have; it’s a critical part of building robust and reliable applications for production. […]
The Shift from Models to Compound AI Systems – The Berkeley Artificial Intelligence Research Blog
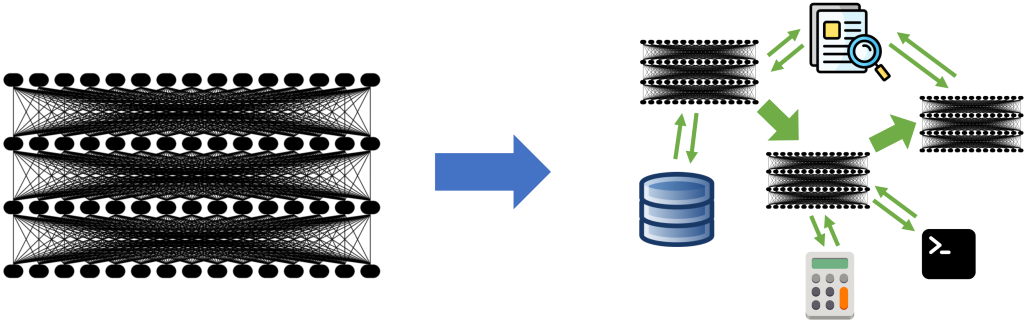
AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. This naturally led to an intense focus on models as the primary ingredient in AI application development, with everyone wondering what capabilities new LLMs will bring. As more […]
Talk to Videos
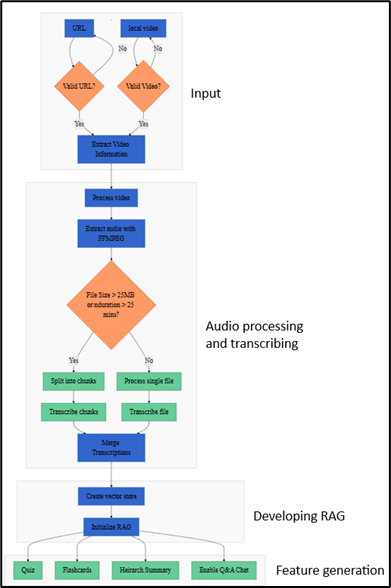
Large language models (LLMs) are improving in efficiency and are now able to understand different data formats, offering possibilities for myriads of applications in different domains. Initially, LLMs were inherently able to process only text. The image understanding feature was integrated by coupling an LLM with another image encoding model. However, gpt-4o was trained on […]
Modeling Extremely Large Images with xT – The Berkeley Artificial Intelligence Research Blog
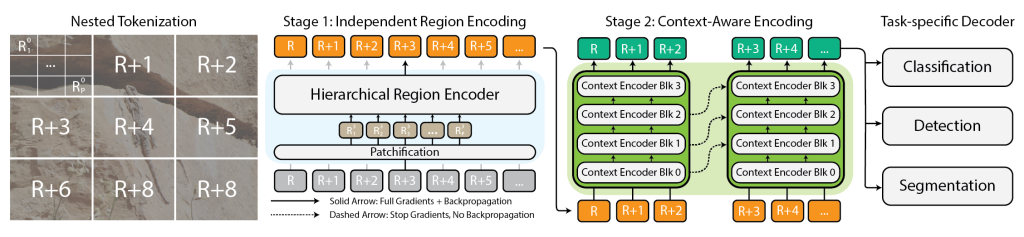
As computer vision researchers, we believe that every pixel can tell a story. However, there seems to be a writer’s block settling into the field when it comes to dealing with large images. Large images are no longer rare—the cameras we carry in our pockets and those orbiting our planet snap pictures so big and […]
AI Agents from Zero to Hero — Part 2
Intro In Part 1 of this tutorial series, we introduced AI Agents, autonomous programs that perform tasks, make decisions, and communicate with others. Agents perform actions through Tools. It might happen that a Tool doesn’t work on the first try, or that multiple Tools must be activated in sequence. Agents should be able to organize […]
Function Calling at the Edge – The Berkeley Artificial Intelligence Research Blog
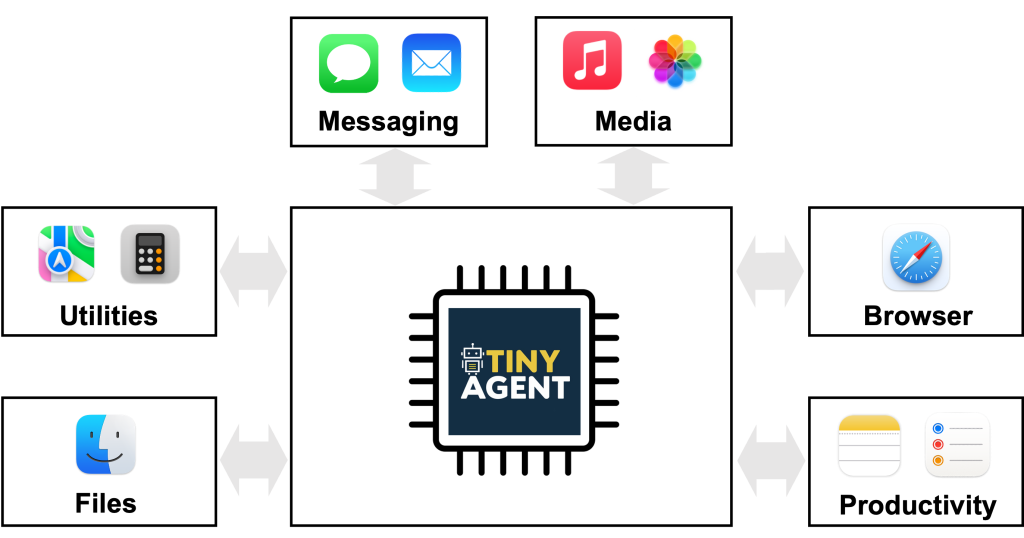
The ability of LLMs to execute commands through plain language (e.g. English) has enabled agentic systems that can complete a user query by orchestrating the right set of tools (e.g. ToolFormer, Gorilla). This, along with the recent multi-modal efforts such as the GPT-4o or Gemini-1.5 model, has expanded the realm of possibilities with AI agents. […]
Automate Supply Chain Analytics Workflows with AI Agents using n8n
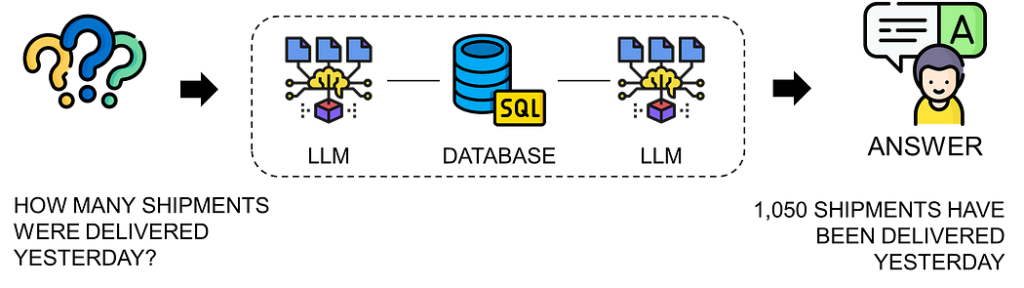
Why build things the hard way when you can design them the smart way? As a Supply Chain Data Scientist, I’ve explored various frameworks like LangChain and LangGraph to build AI agents using Python. Leveraging LLMs with LangChain for Supply Chain Analytics — A Control Tower Powered by GPT — (Image by Samir Saci) The illustration above is from an […]